Guardian Agents in CI/CD: Stop AI-Generated Bugs Before They Ship
Guardian agents catch semantic errors, self-heal tests, and enforce CI/CD quality gates before AI-generated code ships. Architecture, tools, and limits.
If you're shipping AI-generated code without a guardian agent in your pipeline, you're doing code review in the wrong direction - catching bugs after they compile cleanly and pass every lint rule, but before the app calculates tax at the correct rate.
That gap - between syntactic correctness and semantic correctness - is the problem that traditional CI/CD was never built to close. A function that looks right isn't the same as a function that does the right thing, and models like Claude Code, GitHub Copilot, and Cursor generate code fast enough that no human review team can keep up with the volume.
Guardian agents are what fills that gap. They don't generate code - they scrutinize it. This post explains how they work, what the architecture looks like in practice, and where the real limitations are.
TL;DR: Guardian agents are autonomous AI systems embedded in CI/CD pipelines that validate AI-generated code against executable specifications, run self-healing test suites, analyze failure logs, and apply fixes - before deployment. The biggest architectural risk isn't the agents themselves; it's using the same model family to generate and review code.
Why traditional CI/CD fails AI-generated code
Traditional pipelines were designed to catch a specific class of problems: broken builds, failing tests, lint violations, and known security vulnerabilities. Every gate in a conventional pipeline is a syntactic or structural check - it can tell you whether the code compiles, not whether the code is correct.
AI coding tools have created a new failure mode that these gates cannot detect. In the 2025 State of AI Code Quality survey, 82% of developers reported using AI coding tools daily or weekly. The volume of code entering review pipelines has outpaced human reviewer capacity by a wide margin.
Two compounding risks follow from this:
Volume risk: Code generation is now faster than code review. A developer using Claude Code or Cursor can generate several hundred lines of plausible-looking code per session. Reviewing that output with the same diligence as hand-written code isn't realistic at scale.
Correlated failure risk: The dominant response - deploying AI reviewers to catch AI-generated bugs - is structurally circular when the same model family is doing both. Research published in March 2026 (Zietsman, arXiv:2603.25773) demonstrated that same-family LLM pipelines exhibit correlated failures. Models trained on similar distributions converge on the same syntactically plausible but semantically wrong answers. A 2025 study named this the "popularity trap": multi-agent review panels using similar models filter out minority-correct solutions and amplify shared errors.
This isn't solvable by better prompting or larger models. It requires structural changes to how pipelines are built.
What a guardian agent actually does
A guardian agent is an autonomous AI system embedded in the CI/CD pipeline with a single job: verify that code does what the specification says it should do. It is not a code generator. It operates with different objectives - verification over creation - and ideally uses a model family different from the one that generated the code under review.
The four core capabilities most mature implementations combine are:
Semantic validation against specifications
The most important gate missing from traditional pipelines is checking whether generated code matches the intended behavior, not just whether it compiles. AI Output Validators combine two layers of analysis:
- AST-level structural checks: Abstract Syntax Tree analysis verifies function signatures, return types, and structural constraints
- LLM-based semantic checks: A secondary model evaluates the code's logic against a YAML specification schema defining expected business rules and behavior constraints
A payment calculation function can pass every unit test you've written for it and still calculate the wrong tax rate. If the unit tests were generated by the same model that wrote the function, they'll reflect the same misunderstanding. Executable specifications - written before code, not derived from it - provide an external reference that neither model can corrupt.
Self-healing test execution
When UI elements change or environment dependencies shift, conventional test runners produce failures. Developers then spend time updating selectors and assertions - work that is entirely mechanical and unrewarding.
Self-healing test agents adapt in real-time. They use visual recognition alongside code-based locators to maintain test stability when the application changes, automatically repair broken selectors, and only escalate failures that represent genuine behavioral regressions. Teams using AI-powered testing platforms report 85% reductions in test maintenance overhead and 10x faster test creation compared to manual authoring.
The governance risk here is regression masking. If an agent silently repairs a test locator that legitimately should fail, it can hide a real behavioral change. Safe autonomous healing requires all healing activity to be logged, visible, and reviewed on a regular cadence - with pattern-breaking fixes escalated to humans.
Log analysis and root cause identification
When a pipeline fails, a developer's default workflow is: read logs → diagnose → fix → push → repeat. This context-switch loop is expensive and unrewarding, especially for intermittent environment failures that are hard to reproduce.
AI log analysis agents use NLP to distinguish environment failures from product bugs, search internal documentation and historical builds for known solutions, and surface root cause explanations with confidence-scored remediation recommendations. For teams using tools like Nx Cloud, context flows back to the developer's local agent automatically on failure - the developer reviews a final PR rather than intervening at each pipeline stage.
Security scanning with autonomous remediation
Guardian agents integrate with or replace traditional SAST, DAST, and SCA tooling - but add the step that manual security scanning skips: actually fixing what they find.
The full security scanning stack in a production 2026 pipeline typically covers:
- SAST (Static Application Security Testing): Scanning source for hardcoded credentials, insecure cryptography, SQL injection patterns, and the LLM-specific vulnerability patterns that AI-generated code introduces (non-existent package references, example secrets in generated output)
- DAST (Dynamic Application Security Testing): Runtime attack simulation for injection flaws and logic errors
- SCA (Software Composition Analysis): Dependency scanning for known CVEs
- Supply chain security: Container image and artifact provenance validation
- Prompt injection scanning: For teams building AI applications, detecting malicious content in commit messages or code reviews that could hijack agent behavior
The most advanced implementations close the loop entirely: after identifying a root cause, the agent generates a fix, validates it by replaying the CI environment, and either opens a PR or auto-applies the change depending on configured confidence thresholds.
The Pipeline Doctor architecture
The architecture emerging in advanced engineering teams is called the Pipeline Doctor or Interceptor pattern. Rather than a single sequential pipeline with a triage agent at the end, it deploys specialized agents at multiple pipeline stages simultaneously.
Code Push
│
├── [Semantic Validator Agent] - checks against specification schema
│
├── [Security Scanner Agent] - SAST + dependency scan in parallel
│
├── [Test Selection Agent] - identifies impacted test scope
│ │
│ └── [Test Execution Agent] - runs selected suite, self-heals failures
│
├── [Log Doctor Agent] - monitors failures, analyzes root cause
│
└── [Policy Enforcement Agent] - OPA policy-as-code gates
│
└── [Remediation Agent] - generates, validates, proposes/applies fix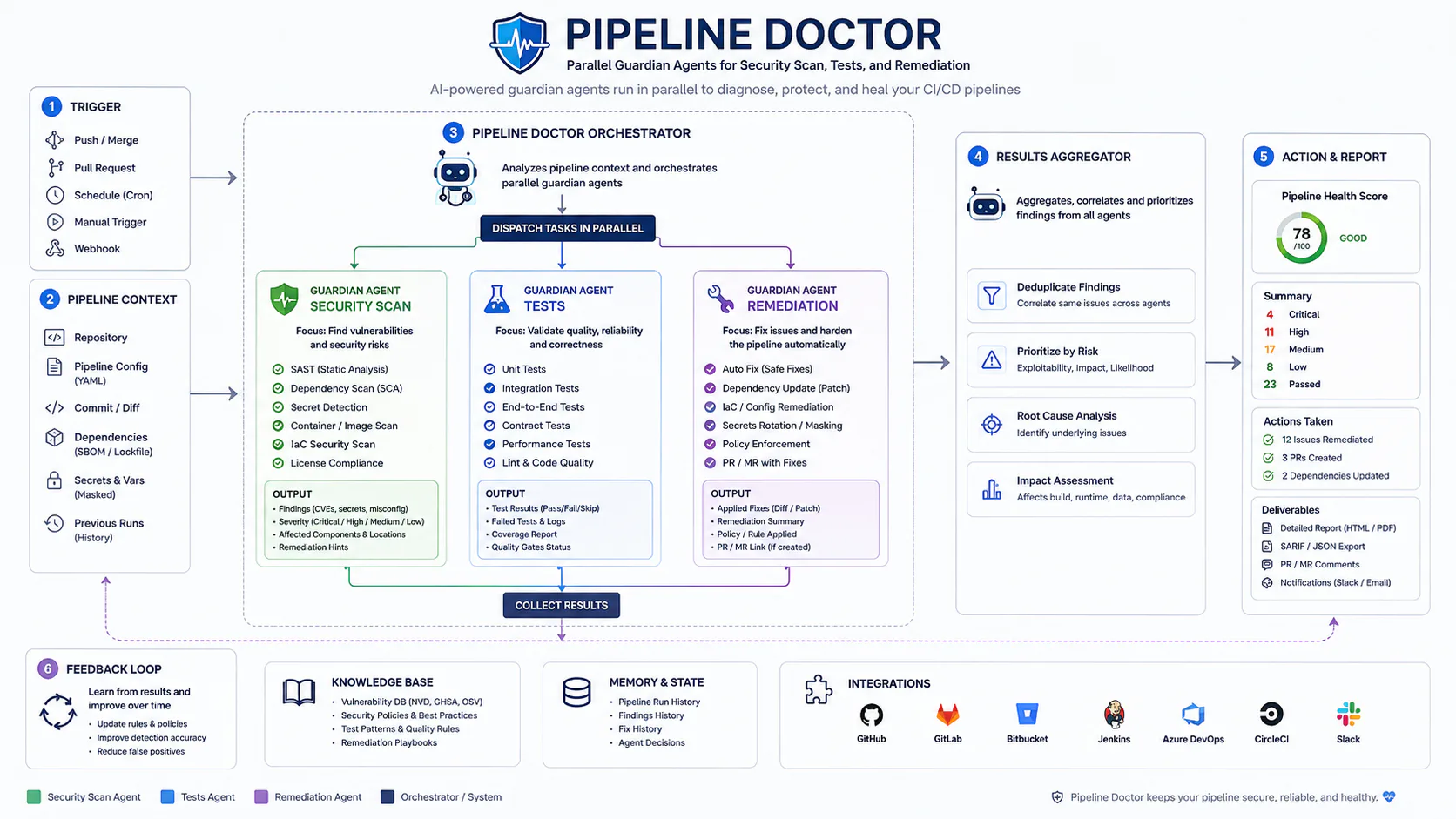
Parallel execution isn't an optimization here - it's a baseline requirement. A pipeline that runs 18 minutes sequentially becomes an 18-hour backlog within hours at scale. The Test Selection Agent alone, by running only tests relevant to the specific code changed rather than the full suite, reduces test cycle times by up to 80%.
Trust tiers: how much autonomy to grant
Every production deployment implements a three-tier trust framework:
| Trust Level | Agent Behavior | Human Role |
|---|---|---|
| Advisory | Flags issues, proposes fixes, never commits | Human approves all changes |
| Semi-Autonomous | Auto-commits high-confidence fixes for low-risk patterns | Human reviews summary, retains override |
| Autonomous | Applies verified fixes within defined scope, escalates outliers | Human sets parameters, monitors dashboards |
Nx Cloud's Self-Healing CI operates at the semi-autonomous tier: auto-apply is enabled when the agent is highly confident, the fix has been re-verified by re-running CI, and the task matches pre-configured scope patterns.
A critical boundary that no current production system crosses: agents only operate at the data plane. An agent that auto-applies a code fix is modifying code artifacts. An agent that modifies approval gates, rollback thresholds, or deployment policy would operate at the control plane - and that authority remains human-only in every publicly documented production system as of 2026.
Adversarial diversity in multi-agent review
The correlated failure problem has a structural solution: deliberately use different model families for generation and review.
Research confirms that cross-family model panels - Claude reviewing GPT-generated code, Gemini reviewing Claude-generated code - recover up to 95% of the gain that a perfectly independent ensemble would achieve. Homogeneous panels amplify shared errors. Adversarial diversity cancels them.
Executable specifications function as the external reference point that makes this work. Instead of checking code against another model's assessment of the code, the pipeline checks code against a ground-truth specification that exists independently of any model's training distribution.
Configuring your pipeline: the AGENTS.md pattern
A practical pattern crystallizing in 2026 is the AGENTS.md file - a repository-level configuration file that CI agents read automatically as system instructions. It is to guardian agents what .cursorrules is to local coding assistants.
# Agent Configuration
## Scope Boundaries
- May modify: src/, tests/, config/
- Must not modify: infrastructure/, .github/workflows/, secrets/
## Codebase Patterns
- All currency calculations must use Decimal, never float
- Tax rate lookups must call the TaxService; never hardcode rates
- Auth checks belong in middleware, not in route handlers
## Self-Healing Behavior
- Auto-apply threshold: 0.90 confidence
- Excluded from auto-apply: database migrations, auth modules
- Escalate for human review: any fix touching payment flows
## Business Context
- This is a multi-tenant B2B SaaS. Every data query must be scoped to org_id.
- The v2 API is deprecated. New code should never reference /api/v2/ endpoints.This file lets you inject business context that code alone cannot supply - which model families generating from training distributions have no other way to know.
LLM-as-Judge for AI application pipelines
Traditional CI/CD is built on binary assertions: X == Y. AI systems are probabilistic: X ≈ Y. When you're deploying an application whose outputs are themselves generated by a language model, hard-coded assertions cannot function.
The 2026 standard design pattern for AI application pipelines is the LLM-as-Judge gate: a secondary, specialized model evaluates the output of the primary AI system against quality thresholds before the build is allowed to proceed.
import anthropic
import json
def evaluate_ai_output(
generated_output: str,
specification: str,
confidence_threshold: float = 0.85
) -> dict:
"""
Gate that blocks deployment when AI output quality falls below threshold.
Returns: {"pass": bool, "score": float, "reason": str}
"""
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
system="""You are a quality gate evaluator. Respond only with valid JSON.
Evaluate whether the generated output meets the specification.
Return: {"pass": bool, "score": float (0.0-1.0), "reason": str}""",
messages=[{
"role": "user",
"content": f"""Specification:
{specification}
Generated Output:
{generated_output}
Does this output meet the specification? Be strict about business logic correctness."""
}]
)
result = json.loads(response.content[0].text)
# Block deployment if below threshold
if result["score"] < confidence_threshold:
result["pass"] = False
return resultLaunchDarkly's AI Config CI/CD pipeline applies this pattern across user segment contexts - testing all configuration variations against premium, free-tier, and enterprise user contexts before any code ships. If quality scores fall below configured thresholds for accuracy, error rate, or latency, the PR is blocked.
TestSprite's benchmark data shows what this gate is worth: applying LLM-as-Judge evaluation to code generated by GPT, Claude Sonnet, and DeepSeek boosted pass rates from 42% to 93% after a single iteration. That's the magnitude of improvement available from systematic pre-deploy validation.
Real-world implementations
Nx Cloud monorepo healing
Nx Cloud Self-Healing CI is the most purpose-built guardian agent platform for CI/CD. It analyzes failures, generates fixes, validates via re-run, and auto-applies changes when confidence is high. Over 50% of generated fixes are rated as useful by clients - and developers save more time from self-healing than from caching and distributed task execution combined.
Its 2026 roadmap targets full end-to-end autonomy: a CI failure triggers the local agent automatically, which iterates on a fix, pushes again, and monitors until green, with the developer reviewing only the final diff.
Limitation to know: Nx Self-Healing CI is Nx-specific. Its value is tightly coupled to the Nx graph that provides full codebase context. For non-Nx monorepos or polyglot stacks, the architectural integration doesn't translate.
GeekyAnts: production self-healing on GitLab
GeekyAnts implemented a production self-healing system using GitLab webhooks to monitor pipeline state. On failure, a Python/FastAPI service fetches logs, queries codebase structure via a Neo4j graph database and Qdrant vector store for failure memory, generates a targeted fix, and validates it locally before submitting as a merge request.
Most failures handled autonomously are routine: dependency version changes, outdated assertions, missing configuration values. The architecture treats CI failures as programmatically solvable problems - not as developer interruptions.
Financial services: compliance-driven guardian agents
Forward-thinking financial services organizations deploy guardian agents as compliance gatekeepers within CI/CD:
- Privacy-impact and vulnerability scans integrated into every pull request
- Automated release approvals requiring explicit sign-off on consumer-protection rules before shipping
- Immutable audit trails of every build, test, and deployment step - serving as regulatory evidence
This use case is accelerating. The EU AI Act becomes fully applicable August 2, 2026, with penalties up to €40M or 7% of global turnover for high-risk agentic systems that lack documented human oversight mechanisms.
The limitations teams underestimate
Correlated failure is structural, not solvable by prompting
If your guardian agent uses the same model family as your code generator, you haven't solved the review problem - you've made it symmetric. Both agents reason from the same training prior. Investing in cross-family review panels and executable specifications is the only structural fix.
Specifications must be maintained
The specification-as-quality-gate framework only works if specifications are kept current. A spec that describes the system as it existed six months ago doesn't gate the system as it exists today. Teams with poor specification hygiene get poor guardian agent results. This is an organizational discipline problem, not a tooling problem.
False positive fatigue is a real failure mode
Security scanning agents, even AI-enhanced ones, generate false positives. Checkmarx One, Snyk, and Veracode have made progress on signal-to-noise, but alert fatigue is documented. If developers learn to override guardian agent alerts because they're too often wrong, the guardrail ceases to function. Tuning confidence thresholds isn't optional - it's the operational work that determines whether agents are useful or ignored.
Pipeline agents can be expensive at commit volume
Running LLM-based semantic checks, parallel agent execution, and LLM-as-Judge evaluation on every commit at high deployment frequency requires careful token budgeting. GitHub Copilot's transition to usage-based billing (AI Credits based on token consumption, effective June 1, 2026) is a signal of where the market is heading. FinOps guardrails - strict token-usage tracking and rate limiting per pipeline agent - are an operational necessity.
Self-healing can mask regressions
The most dangerous failure mode of autonomous test healing is silence. When an agent repairs a broken test locator, it may also silently accept a behavioral change that should have failed the build. Governance requires all healing activity to be visible, auditable, and reviewed on a cadence - with mandatory escalation for pattern-breaking fixes.
Who should adopt guardian agents now vs. later
Use guardian agents now if:
- You're generating significant volumes of AI-assisted code daily and human review is a throughput bottleneck
- You're operating in a regulated industry (fintech, health, enterprise SaaS) where audit trails and compliance gates have direct regulatory value
- You're running a large monorepo with Nx - Nx Self-Healing CI integrates natively and provides immediate ROI
- Your test suite maintenance overhead is consuming meaningful engineering time
Wait if:
- Your AI code volume is low enough that manual review is still viable - the infrastructure overhead won't pay off yet
- Your specifications are not maintained - guardian agents need ground truth to validate against
- You haven't established FinOps controls for AI inference costs - unmanaged pipeline agents at scale generate significant unexpected spend
- Your team hasn't defined trust tiers and approval gate design - deploying autonomous agents without governance is worse than deploying no agents
The practical takeaway
Guardian agents are not a future concept - they're a 2026 operational requirement for teams shipping AI-generated code at scale. The underlying problem they solve is real and won't improve on its own: AI code generators and traditional pipelines have a structural mismatch, and the naive fix (adding more AI reviewers) makes it worse without adversarial diversity.
The teams getting the most value now are those combining three elements: executable specifications as external reference, cross-family model panels for review, and staged autonomy with human-retained control-plane authority. That's the architecture worth building toward.
For the code-generation side of the stack that guardian agents review, see our Cursor 3 review (parallel agents and cloud coding). For teams building on top of pipeline APIs, our developer tools category hub covers the broader ecosystem.
Frequently asked questions
A guardian agent is an autonomous AI system embedded in a CI/CD pipeline that validates code against specifications, runs self-healing test suites, analyzes failure logs, and proposes or applies fixes - before deployment. Unlike coding assistants that generate code, guardian agents verify it, operating with adversarial objectives distinct from the model that wrote the code under review.
PR-level AI code review tools (CodeRabbit, Greptile, Devin) analyze pull requests at the merge gate and generate review comments. Guardian agents are pipeline-native: they run in parallel with your build stages, enforce executable specifications as quality gates, self-heal failing tests, analyze CI logs, and optionally apply fixes autonomously. The distinction is depth of pipeline integration and the ability to act, not just comment.
When the same model family generates and reviews code, both agents reason from the same training distribution. The reviewer checks code against shared priors, not against ground truth - so systematic misunderstandings in the generator are invisible to the reviewer. The fix is structural: use cross-family model panels (Claude reviewing GPT-generated code, for example) and executable specifications as external reference points that no model can corrupt.
The EU AI Act becomes fully applicable August 2, 2026. High-risk agentic systems require documented human oversight mechanisms and audit trails. Penalties reach €40M or 7% of global turnover for non-compliant deployments. The practical implication: every production guardian agent deployment needs a clear trust tier framework, a data plane/control plane boundary (agents modify code, not governance policies), and immutable audit logs of every autonomous action.
Cost scales with commit volume and which gates you run on every push. Semantic validation, LLM-as-Judge evaluation, and parallel agent stages can consume significant tokens per build. Teams at high deployment frequency need FinOps guardrails: per-agent rate limits, running expensive checks only on changed paths, and cheaper models for low-risk tasks. Treat pipeline inference like any other cloud bill - cap it before autonomy is turned up.


